Gestione informativa digitale e intelligenza artificiale: un dialogo coerente?
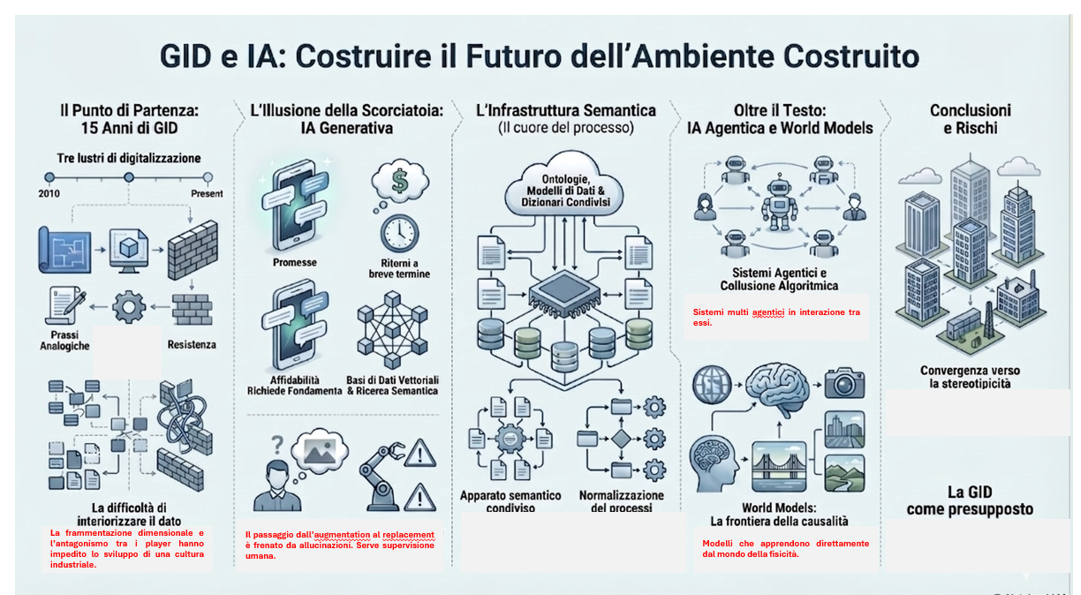
È ormai da un quindicennio, vale a dire da tre lustri, che il settore della costruzione e dell’immobiliare, meglio definibile come settore dell’ambiente costruito, si confronta con i temi della digitalizzazione, a partire dalla Modellazione informativa, il solo sotto insieme della Gestione Informativa Digitale che abbia ricevuto un riconoscimento legislativo in termini di cogenza, benché, ad esempio, le applicazioni di Internet of Things ai macchinari di cantiere abbiano goduto di importanti agevolazioni fiscali.
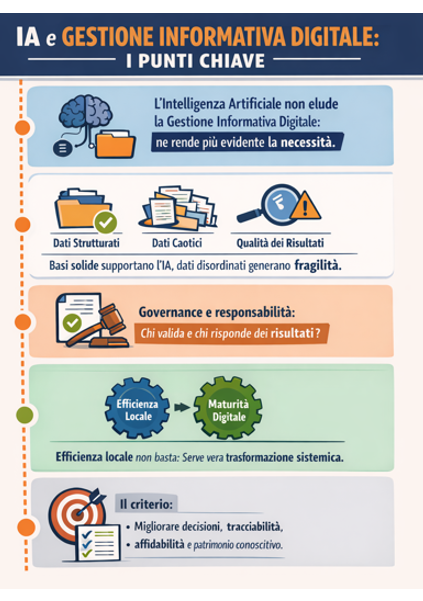
Ciò che si può affermare è che, tuttavia, gli attori della domanda e dell’offerta, di là da eccezioni e scontando narrazioni ottimistiche, ma non sempre fattuali, abbiano incontrato notevoli difficoltà a interiorizzare la cultura del dato.
Ciò è dovuto a molteplici ragioni, tra cui il radicamento delle prassi analogiche (che hanno impedito già nel secolo scorso la diffusione di una autentica cultura industriale), la frammentazione dimensionale con le conseguenti problematiche economie (di conoscenza, anzitutto), le contrapposizioni identitarie, e così via.
Soprattutto, la digitalizzazione avrebbe implicato ritorni sul medio periodo e l’adesione cooperativa dei diversi soggetti coinvolti: per il primo caso, la natura costitutiva degli operatori economici (ma anche delle strutture di committenza) non consente una logica se non di breve termine; per la seconda evenienza, l’essenza, appunto, identitaria dei player rende loro indispensabile una sorta di antagonismo.
In più, sul piano strettamente operativo, a dispetto delle retoriche sulla irreversibilità del fenomeno, non si è palesato lo stato di necessità, rinvenibile in altri settori economici.
In apparenza, questa situazione pare essere sconvolta e invertita dall’avvento delle soluzioni di Intelligenza Artificiale Generativa (le più scontate, a dire il vero) che sembrano promettere prospettive antitetiche: interlocuzioni a livello conversazionale sul piano documentale (assai familiare), ritorni a breve termine, e così via.
Di ciò è testimone, a titolo esemplificativo, l’entusiasmo con cui stazioni appaltanti e imprese di costruzioni stanno implementando soluzioni di questo genere per la gestione dei processi di affidamento dei contratti, pubblici o privati.
Occorre, però, domandarsi se una simile interpretazione possa corrispondere alla realtà.
Di fatto, il processo trasformativo legato alla digitalizzazione iniziato tre lustri or sono comportava l’obiettivo di procedere a una normalizzazione dei processi gestionali e delle transazioni informative, implicando la costituzione consensuale di un apparato semantico condiviso, alimentato da ontologie, modelli di dati, dizionari di dati, e così via.
Nel momento in cui, al fine di mettere a profitto le soluzioni di Intelligenza Artificiale si rende inevitabile porre in essere questa architettura infrastrutturale dell’ecosistema siffatto, le aspettative semplicistiche inerenti all’Intelligenza Artificiale potrebbero venire meno.
Si vuole dire che certamente i dispositivi paiono efficienti nella ingestion documentale e nell’analisi dei loro contenuti.
Ciò vale anche per i Modelli Linguistici Multi Modali, che trattano fonti non solo testuali.
La prima questione sorge a proposito della configurazione di basi di dati, eventualmente vettoriali, che consentano un retrieval performante, vale a dire, la ricerca semantica utile a individuare testi, immagini o altro, strutturate in precedenza e attinenti alle esperienze pregresse dell’organizzazione, qui capitalizzabili come gestione della conoscenza per effettuare attività di matching.
Non è per nulla che sia stata recentemente pubblicata una prassi di riferimento britannica che basa le evoluzioni della Intelligenza Artificiale Generativa sulla normalizzazione di un apparato di processi, di metodi, di contenuti e così via.
Tenendo in considerazione la necessità di tutelare il proprio patrimonio conoscitivo, sostanzialmente elemento cruciale come fattore competitivo, è palese che il settore debba riflettere sulle modalità di condivisione di basi di dati.
Naturalmente, poiché sempre più ci si sta avvicinando a una interazione diretta, o quanto meno mediata in misura minore, tra Modelli Linguistici e Modelli Informativi, anche questi ultimi concorrono a realizzare il patrimonio di dati e di informazioni storiche di una organizzazione da riutilizzare.
Se, comunque, la fase istruttoria ha a che fare essenzialmente colla velocizzazione dei processi, richiedendo, peraltro, una attenta supervisione da parte dell’esperto umano, quella di recupero di elementi pregressi e di loro rielaborazione per impostare la prima versione di un documento, di una immagine, di un video o di un Modello Informativo (e dei relativi elaborati grafici), passa dal potenziamento (augmentation) a una prima parziale ipotesi di sostituzione (replacement).
D’altra parte, considerando allucinazioni, scheming, reward hacking e altre forme di misalingment rispetto ai prompt forniti dal soggetto umano, occorre verificare quanto si possa dare un incremento qualitativo e in che misura la velocizzazione dei passaggi iniziali non debba poi essere ritardata da attente verifiche successive: come forse già accade per il coding.
Sotto questo profilo, la rapidità e l’esaustività caratteristiche delle risposte fornite dai dispositivi generativi richiedono, a ogni buon conto, un innalzamento delle competenze delle risorse umane dedicate, piuttosto che non la loro riduzione o eliminazione entro processi completamente automatizzati, poco, del resto, praticabili giuridicamente, a fronte della legislazione europea e italiana.
Quello che si profila, invero, è la possibilità che si registri una convergenza algoritmica tra le soluzioni proposte in termini concorrenziali tra gli operatori o nel rapporto tra le parti in causa nei contratti, cosicché il miglioramento delle prestazioni medie degli attori conduca a condizioni di eccessiva omogeneità e stereotipicità.
Per altri versi, i sistemi generativi potrebbero agevolare la capacità di mettere in relazione, di interrogare e di elaborare dati e informazioni che risiedono in contenitori informativi assai eterogenei e di aggiornarli anche tramite fonti esterne, mettendo anche in discussione i confini tra dati strutturati o meno.
Certamente, a partire dai cosiddetti Digital Twin, si intravedono ecosistemi digitali in grado non solo di supportare il processo decisionale, ma pure, almeno in parte, di attuarlo semi autonomamente.
Da questo punto di vista, allo stato attuale, si tratta di comprendere se la diffusione dei dispositivi generativi contribuisca a rendere più praticabile la digitalizzazione nelle sue molteplici manifestazioni, inclusa la Modellazione Informativa e la Gestione Informativa Digitale, oppure se ne rappresenti l’antitesi, nel senso di renderla superflua.
Il quesito attraversa, infatti, quella condizione prodromica di normalizzazione dei quadri procedurali e operativi che sinora il settore ha nei fatti rigettato con forza, anche se tacitamente.
Altro punto sensibile è offerto dalla crescente disponibilità di sistemi agentici, che ampliano e potenziano gli interrogativi, dato che prevedono azioni di istruttoria, di rettifica e di validazione umana molto più complesse e articolate, condizioni di indipendenza e di autonomia del dispositivo multi agentico accentuate, interazione diretta tra sistemi agentici delle diverse organizzazioni poco intelleggibili, tanto da giungere alla cosiddetta collusione algoritmica.
In questo caso, urge la disponibilità di risorse umane in misura minore, ma molto qualificate e predisposte al dialogo con l’algoritmo, e si restringe lo spazio decisionale affidato all’essere umano.
Se, perciò, si rendesse necessario predisporre Modelli Linguistici Multi Modali adeguati ai bisogni specifici del settore, tanto più questa condizione varrebbe per l’Intelligenza Artificiale Agentica.
Sullo sfondo, infine, si agita il tema dei World Model, nel senso che i Modelli Mondiali pongono radicalmente in discussione la natura dei Modelli Linguistici rispetto non solo al fatto di dipendere da logiche probabilistiche, ma, soprattutto, di non possedere una comprensione causale e una esperienza non mediata dei contesti reali.
Vi è una sottovalutazione della portata di questi approcci: essi, qualora si dimostrassero spendibili sottintenderebbero una rappresentazione interna della realtà fisica come causalità, dinamiche spazio temporali, conseguenze delle azioni.
In definitiva, i Modelli Mondiali potrebbero aggirare la necessità di possedere l’infrastruttura semantica, poiché l’apprendimento non sarebbe mediato dai documenti, ma sarebbe diretto dal mondo fisico, rendendo parzialmente superflua la costruzione attuale della cultura del dato.
Che poi, l’apprendimento e l’addestramento da parte di queste soluzioni possa avvenire esclusivamente attraverso immagini e video che restituiscono le dinamiche fisiche reali è da vedere, ma si tratta di evadere dai confini di un contesto puramente testuale, in senso lato.
Qualora i Modelli Mondiali si dimostrassero efficaci e venissero inevitabilmente incorporati in entità fisiche, le loro capacità, probabilmente superiori a quelle dei sistemi agentici, costringerebbero a una revisione più profonda dell’ecosistema digitale che il settore dell’ambiente costruito sta promuovendo.
Il rischio maggiore che si può agevolmente percepire oggi è una forte cortomiranza sia nei confronti della Gestione Informativa Digitale, che resta un fenomeno superficiale ed estraneo all’operatività minuta degli attori, sia nei confronti dell’Intelligenza Artificiale che, al contrario, i player vorrebbero immediatamente attuare.
Di conseguenza, è doveroso riconoscere come sino a che gli attori del settore non avranno pienamente aderito alle logiche tipiche della Gestione Informativa Digitale, quale presupposto, difficilmente le applicazioni dell’Intelligenza Artificiale potranno oltrepassare una sorta di dimensione rapsodica, per certi versi contingente.
In assenza di una adeguata infrastruttura semantica, procedurale e informativa, l’Intelligenza Artificiale rischia di esaurire ben presto il potenziale atteso.
Parimenti, tutte le preoccupazioni mostrate in relazione alla definizione delle responsabilità, alla determinazione delle soglie di validazione e alla individuazione dei presidi di controllo potrebbero dimostrarsi tendenzialmente velleitarie.